
Let's time travel to the 16th century Renaissance period, where Raphael is working on his famous fresco - The School of Athens - one of the all-time historic paintings.
We see two of the greatest philosophers. On the left, we have Plato and his disciples. On the right, we have his student Aristotle and his followers. They portray a complex dichotomy - two different schools of thought.

Plato is pointing up in the sky, while Aristotle is pointing to the ground.
Plato's expression toward the sky indicates the idea of abstraction. Aristotle's gesture toward the ground depicts the belief of knowledge based on experience — empiricism. While abstractions have value, Aristotle sheds light on an equally important dimension that highlights the necessity to conduct real-world evaluation and emphasizes the importance of measurement.
This post shines a light on an equally important dimension of LLM-based bots. While there is a lot of noise around building an LLM bot, many miss the critical aspect of evaluation, causing a huge blind spot. For the first time, I will go deep and disect the topic of evaluation.
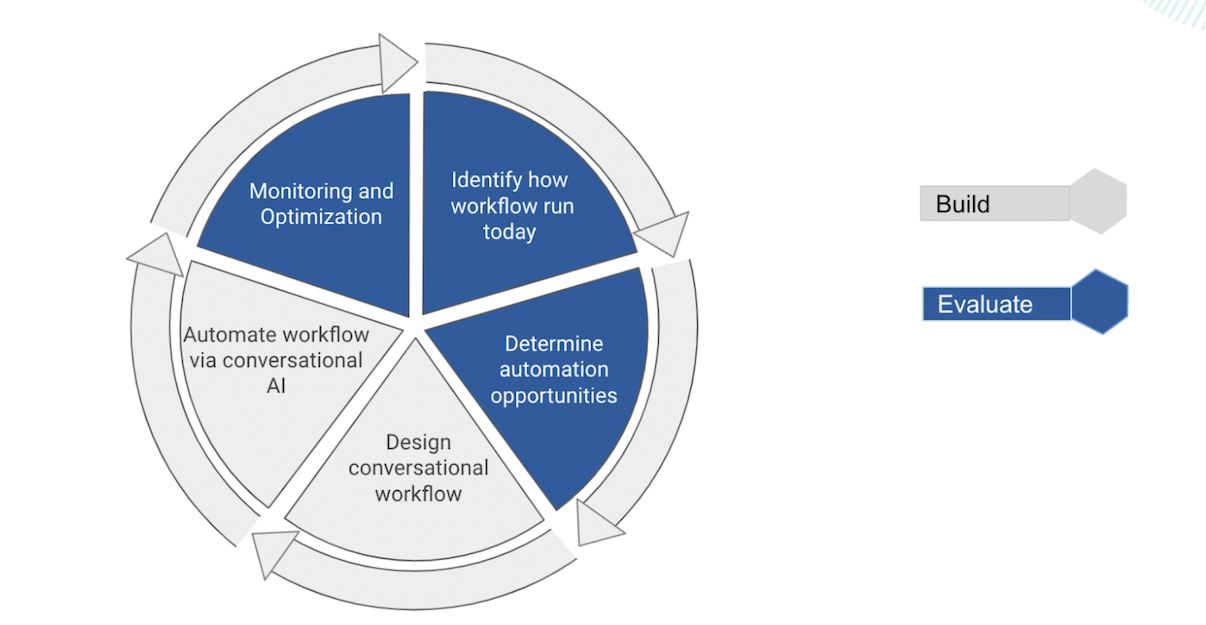
Before we jump into the world of LLM, it is noteworthy to acknowledge that evaluation steps existed before as well.
These include identifying how workflows are run currently and determining automation opportunities. Post automation, there is monitoring, A/B test, and continuous optimization. And the cycle repeats. Evaluation and building go hand in hand.

However, the evaluation needs snowballs in the LLM era.
It is challenging to evaluate prompts in the real world and surface hotspots where they are failing and how to fix them. In real-world B2B applications, there is a probability of factual nonsense or otherwise hallucinations. How do you identify when that is happening, and intervene? Lastly, LLMs are sophisticated black boxes. There is no observability and monitoring. Measuring business value requires a deeper understanding of the actual conversation data.
With that backstory, let's dive deeper into five new blind spots to avoid when it comes to LLM bots. These are the top areas conversational AI teams are acting upon, to deploy successful applications in production.
Real World Prompt Evaluation
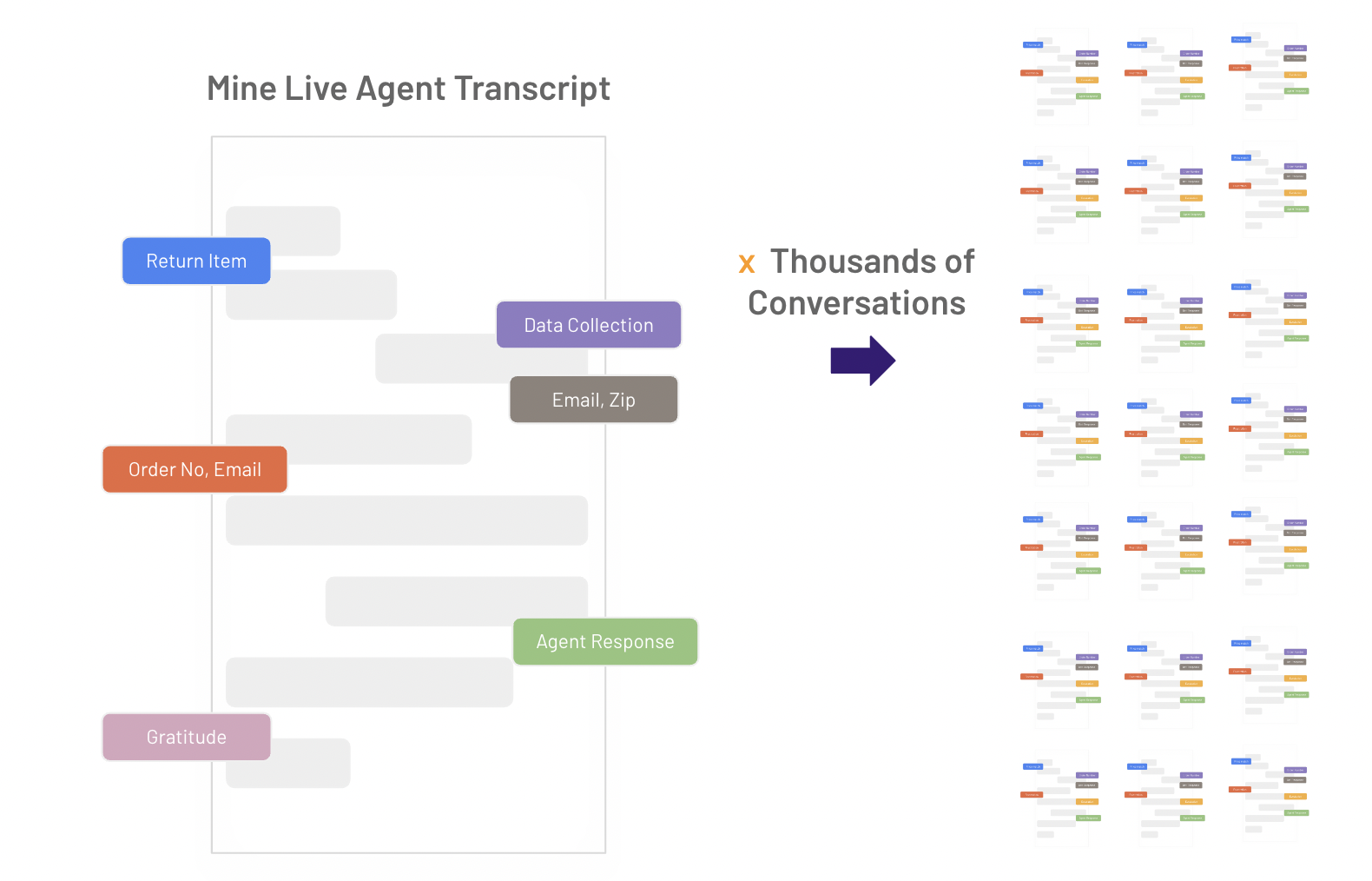
One of the aspects of this evaluation is setting up the data to try generative models. How do you know what should be the right prompt to manage real world use cases? The secret insight is to leverage existing human agent interactions to automatically generate conversation flow prompts for your domain and use case.
How does it work?
1. Mine dialogs from human agent transcripts - user query, data collected to clarify user query, agent actions, etc. Then, you aggregate that for thousands of conversations.
2️. Now, you start seeing real world conversation flows and variations that bubble up. See below for an e-commerce example.
3️. Map the conversation flow into a prompt to mimic the real-world scenario.

Once you do that, you start seeing real world conversation flows and variations that bubbles up. For instance, in the ecommerce scenario above, one of the top flows is around returning items. The data collected includes order number, email and zip code. Depending on that data, there are two possible responses - one around returning directly to the store and one around emailing a pre-paid smart label.

This is then translated into a prompt reflecting the real-world flow. Notice how the prompt is engineered to ask for specific information like ordering number to fulfill the return query. And how the purchase type (online or in-store) drives separate responses.
Regression test via simulation
So you have your prompt all setup and ready to deploy to production. However, you have this lingering concern about the "what ifs." You are worried about production deployment without running regression tests on the prompts and flow you designed.
How does the LLM react to various inputs and deviations? Is it able to recover? Are there some flaws in the prompt design?
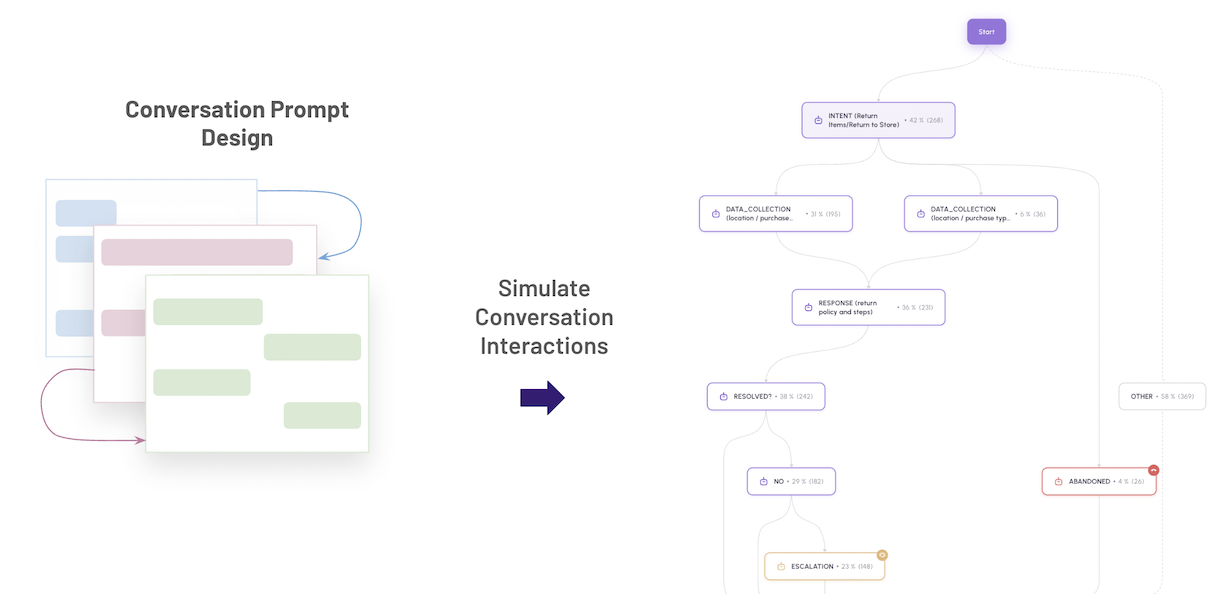
Would it not be helpful to simulate entire conversations and do that many times, aggregate all the flows and visualize the simulated conversations for problem areas such as escalations, abandonments, and unsolved problems?
That is where conversation flow simulations to conduct regression tests are a blessing - a critical step in evaluating the bot design.
Deep Conversation Metrics
How do you measure the value of LLMs in the real world? You can measure using deep conversation metrics that analyze multi-turn conversation sequences to compute how well the LLM is performing with a real-world user on the other side.
Some leading metrics are as follows:
Inferred CSAT - CSAT score automatically computed for 100% of conversations in real time without relying on post interaction surveys. The latter tend to be biased, less objective and a lagging indicator.
Resolution Rate - was the user issue actually solved by the bot?
Effort Score - how difficult was it for the user to get help? These include length of the conversation, amount of rephrasing and restating context, loops they had to go through etc.
In addition to the numbers, you need to know the why behind the numbers to make them actionable. For example, what are the top positive and negative factors which impacted the inferred CSAT.
Here is a concrete scenario, where reassurance and follow-ups is a positive factor with medium weight. So designing the bot prompts to make the bot reassuring and providing follow-up steps even when the problem is difficult to solve, can improve customer satisfaction and thereby retention.

Policy and Brand Deviations
Almost all customer support use cases have underlying policies. Companies have specific brand guidelines and care about the verbiage and tone of customer support interactions.
But LLM bots can often go off the rails.
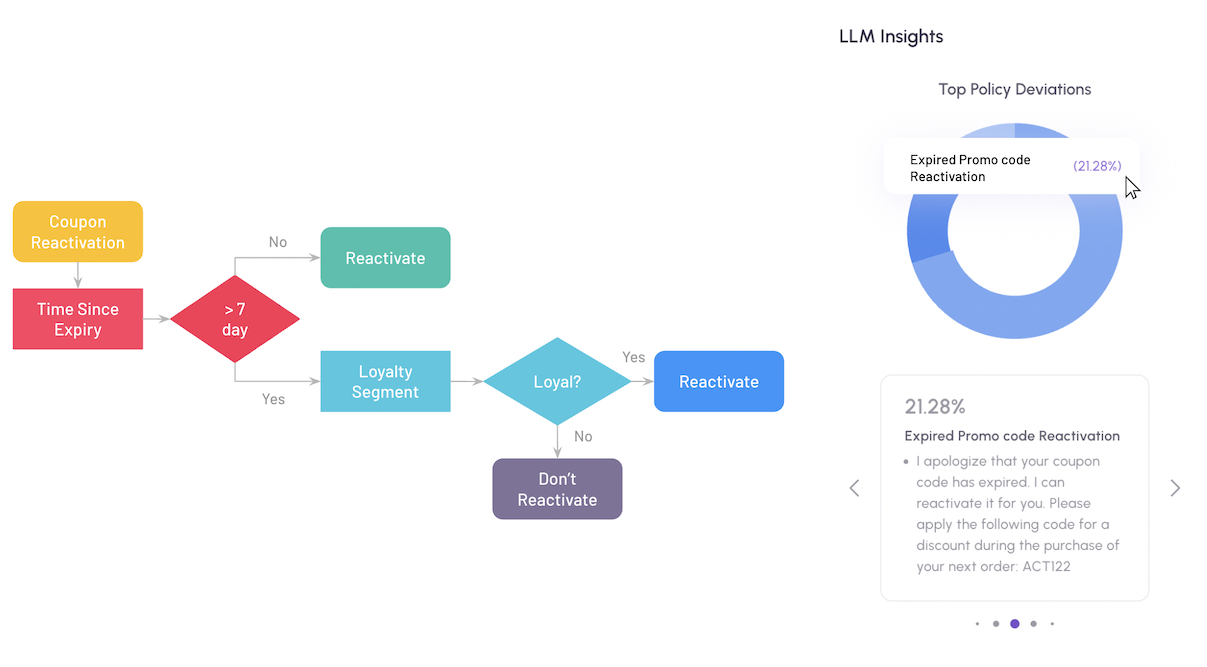
In the example below, an LLM bot fails to adhere to a coupon/discount code policy. It is a use case of reactivating an expired coupon code under certain circumstances.
The policy states that one can reactivate an expired coupon code if it is under 7 days from the expiry date. However, beyond 7 days, it can only be reactivated for loyal customer segments. With LLMs, you cannot guarantee such policies are abided by.
There needs to be continuous monitoring to detect such violations. What are the top policy deviations? What percentage of times does it occur? What is the nature of those deviations? That is crucial for any production deployment.
Conversation Flow Insights and Observability
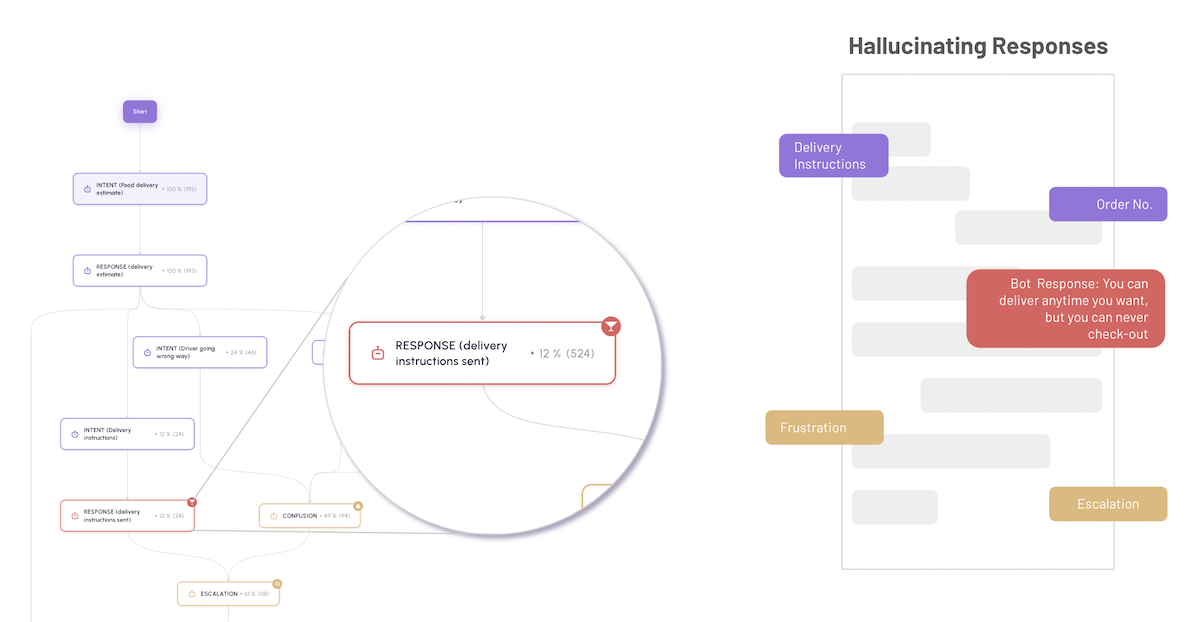
Finally, LLMs are black box in nature. You can turn that around with observability and monitoring by mining conversation flows and surfacing flow insights. Such insights visualize how users interact with your bot and help diagnose breaking points, dialog hot spots, prompt failures, systematic inaccurate responses, and hallucinations, and enable A/B testing of different flows.
Below is an example flow visualization of a food delivery provider where users are asking for food delivery estimates and need to provide special delivery instructions. Analyzing the flow provides insights like bot hallucinations in their responses, which results in user frustration and escalation to a human representative.
Understanding the primary flows and responses from the bot that are systematically inaccurate is an essential step in fixing such issues and improving customer experience.
Parting Thoughts
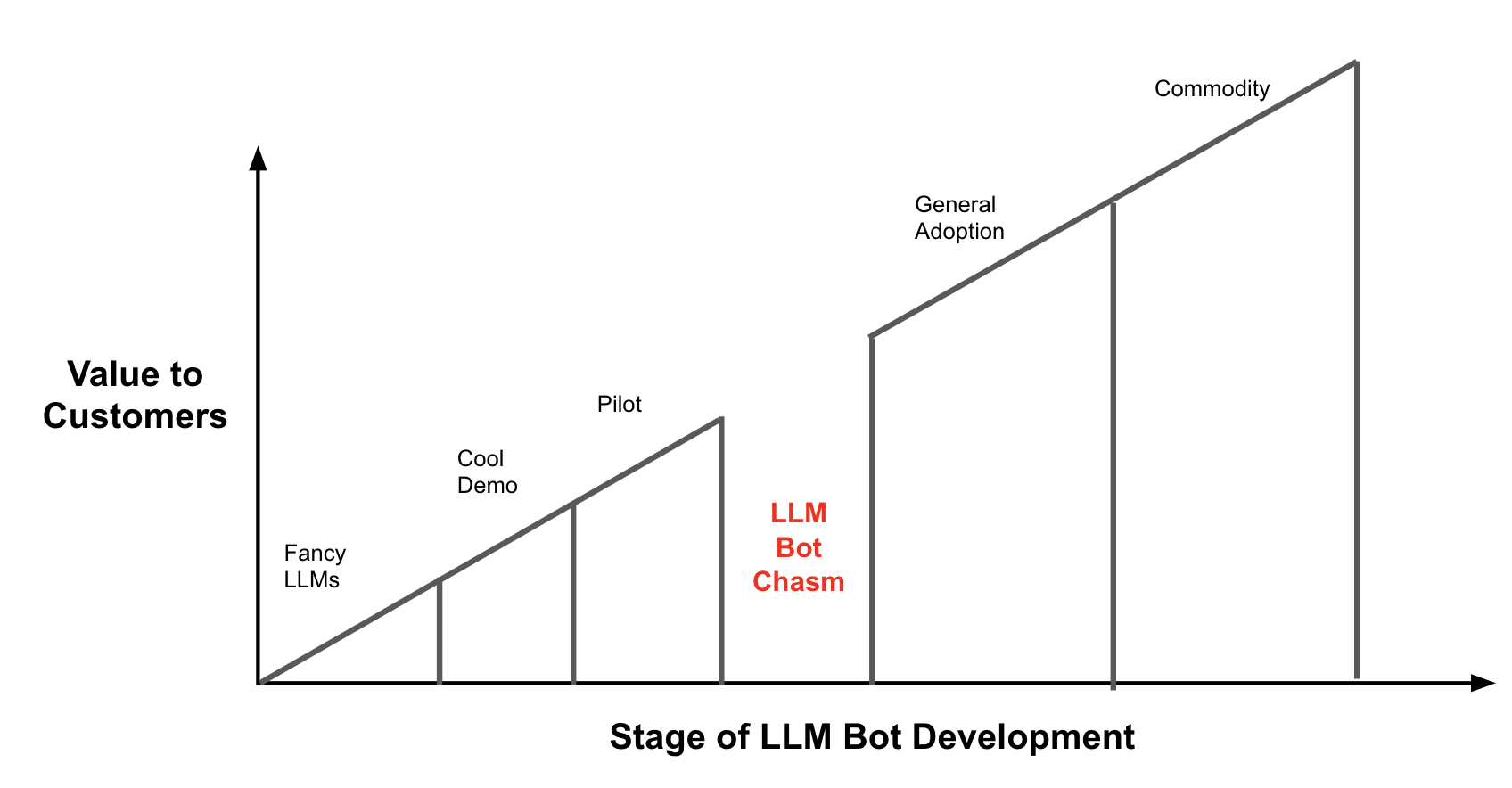
The central message is as follows. No matter how great your LLM is, or how cool your demo is, the LLM Bot chasm will likely be a barrier to general adoption of your conversational AI application.
As LLM pervades, conversational AI teams need an evaluation toolset to cross the chasm and build bots which actually adds value in the real world scenarios and improves CX, as opposed to building just a cool technology feature.
Building vs evaluating LLM bots mirror the contrast in Raphael's fresco. If we look closer at the characters in his work, we see further confirmation of this dichotomy. On the left — Plato's side of the fresco resides Pythagoras, who teaches from a book about the philosophy that every soul transcends the reality we see. On Aristotle's side, we have Euclid, known for geometry, demonstrating something with a compass and emphasizing the importance of measurement and practicality.



